最近这段时间,国内外模型更新得很快。
如果只看发布会和榜单,大家都会觉得每个模型都很强。参数更大、上下文更长、推理更强、价格更低,听起来都挺猛。
但真正用到工作流里,会发现另一件事:模型强不强,不只看它会不会回答问题,还要看它能不能把一个任务完整跑完。
尤其是 Agent 场景。
一个复合任务需要大模型去调用多个工具,比如让模型做一份 PPT,它并不是简单写几页文字。中间要先理解需求,再去搜索资料,阅读网页,提取关键信息,整理成汇报结构,必要时还要生成代码或调用插件,最后产出一个可以正常使用的PPT文件。
下面测试两个Agent任务,使用同样的提示词,相同的Agent工具-Trae Work。
PPT制作
提示词:
调研当前主流短视频平台的差异化优势和发展路径,并整理成一份汇报的演示稿件。 调研范围包括平台基本情况、用户规模、内容生态、推荐机制、商业化模式以及代表性案例。重点对比不同平台在用户群体、内容类型和增长策略方面的差异,并总结其成功经验与未来趋势,为产品或市场策略提供参考。
Step 3.7 Flash
Step 3.7 Flash 收到指令后会根据提示词的需求,进行分析,然后检索对应网站信息,归纳信息最后调用PPT插件工具制作幻灯片文件。



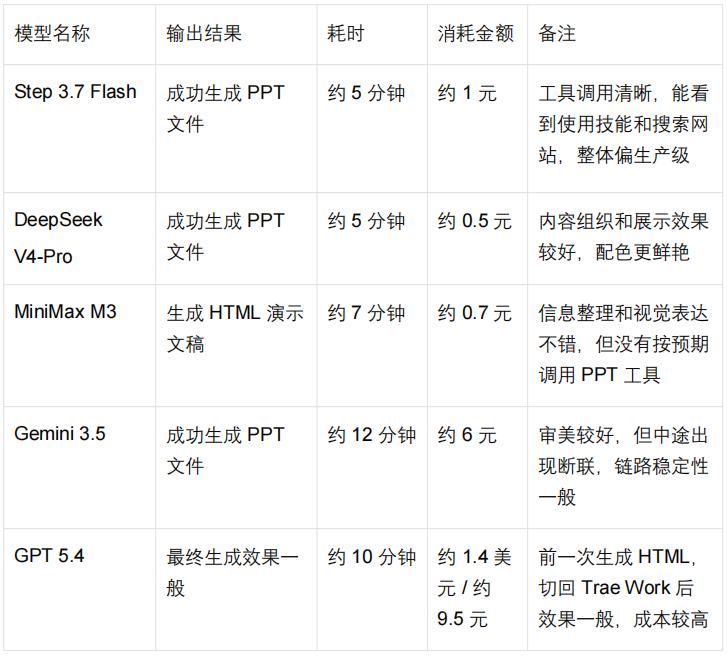
风格偏向简约风格。耗时在5分钟左右,消耗差不多1块。

这个也可以明显的查看到,此次任务使用了什么技能和搜索了什么网站。
整体看下来,Step 3.7 Flash 更像是偏生产级的选择。
它的优势不一定是单页 PPT 最漂亮,而是在速度、工具调用和任务完成率之间比较平衡。高频、多轮、需要稳定交付的 Agent 任务,会比较适合它。
DeepSeek v4-Pro
DeepSeek v4-Pro也是同样的路径,识别任务然后找到需要调用的工具,PPT生成工具。
只不过配色方面要鲜艳一点。最后一步也成功调用了PPT工具。


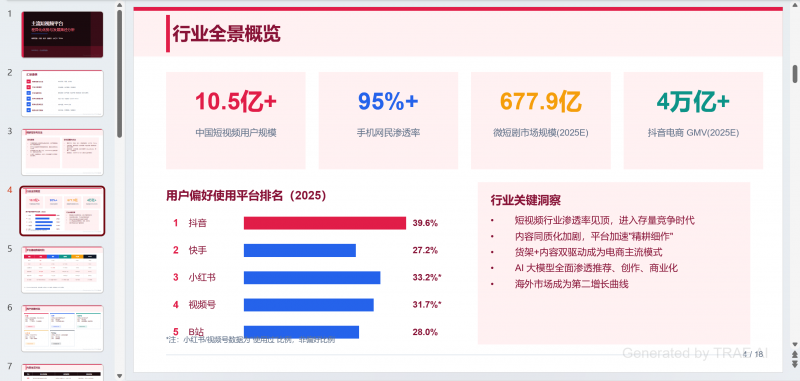
耗时差不多5分钟,token消耗在0.5左右。
简单说,DeepSeek V4 的优势是内容组织和展示效果比较好,适合对成品表达有要求的场景。但如果是持续高频跑 Agent 流水线,还要继续看端到端速度和单次成本。
Minimax
调用Minimax执行这个Agent任务有些不同,同样的提示词,Minimax最后一步调用的HTML工具制作的演示文稿。正常来说应该要去调用PPT工具。既然调用了HTML生成工具,看看生成效果怎么样。
HTML整体画面风格还是可以的,因为是HTML所有代码要好生成一些,如果是制作PPT,可能就没有这么好把控。
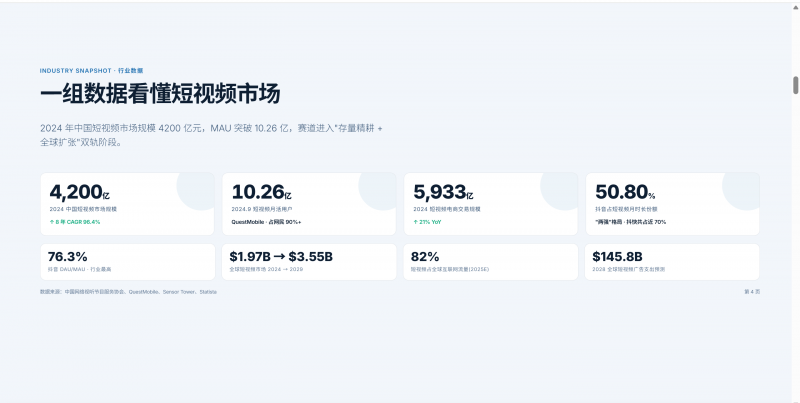
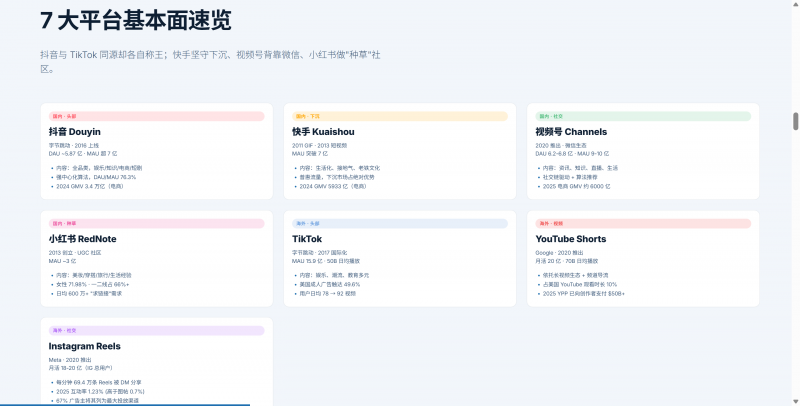
风格偏向清新风格,数据这方面比较齐全的。耗时差不多在7分钟左右,金额消耗0.7。

所以 MiniMax M3 在这次测试里表现出不错的信息整理能力和视觉表达能力,但工具选择的可控性还需要关注。
它适合内容页、网页报告、轻量演示类任务;如果是严格办公格式,比如 PPT、Word、Excel,最好在 Prompt 里把输出格式写得更死一点。
Gemini3.5
Gemini系列的模型,审美一直在线,但是有一个实际问题就是-不稳定。
而且运行效率比较慢,国内模型的话这个PPT任务在3分钟内可以搞定,但是使用Gemini3.5现在粗略估计已经运行了10分钟了,还异常打断了一次。
如果在官方的工具中进行调用的话,那么会稳定一些。关键是谷歌的官方工具Google Antigravity也用不了呀。
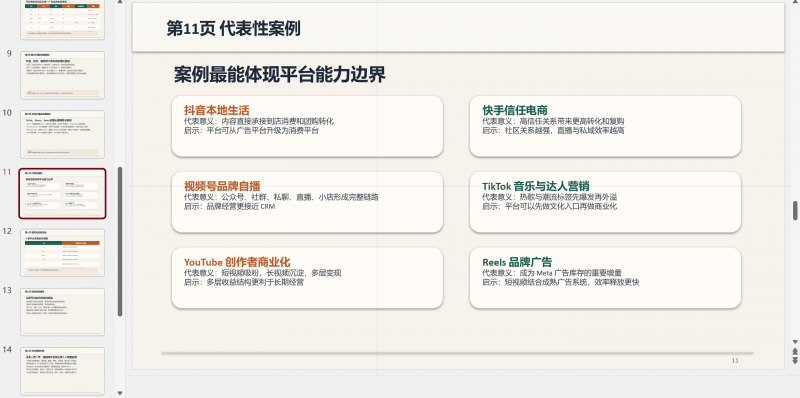
下面是生成的PPT结果。

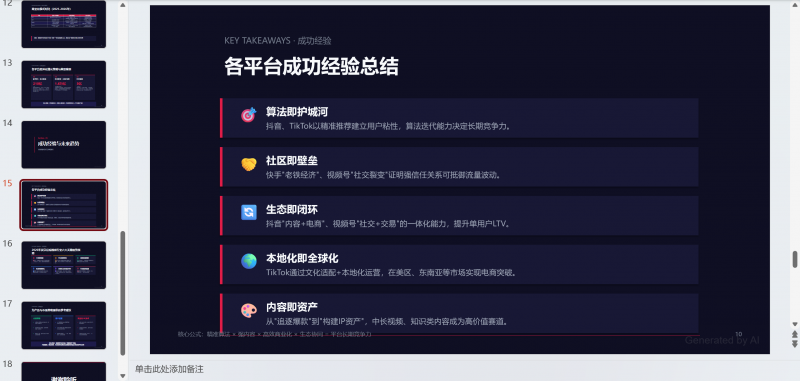
如果任务异常打断的话,会影响到任务链路会变得不连贯,最后导致成品一致性会变差。
这个是最后制作出来的,耗时差不多12分钟。因为中间有断联情况。
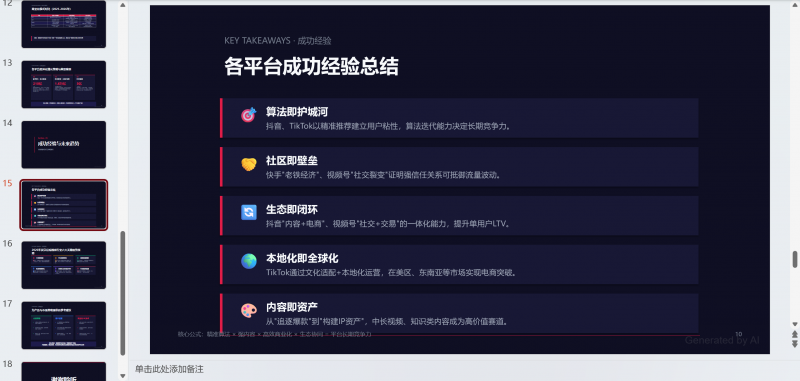
所以 Gemini 3.5 的优势更偏视觉审美和内容表达,适合对页面质感要求高的任务。短板是端到端效率和链路稳定性。
对于高频、低延迟、生产级 Agent 场景,这个问题会被放大。
GPT 5.4
GPT的模型在国外主流模型中,可能没有很突出的方面,但是比较全能。毕竟GPT是模型界的老大哥。
这里我使用的工具是MonkeyCode,因为这个平台可以免费使用GPT5.4.
同样的提示词这个是制作效果:

这个和MiniMax一样直接做成了一个HTML。很明显不是我们想要的PPT文件。
可能是工具没有选对。 切回统一的Agent工具Trae Work。


效果一般,不是很突出。

使用费用在1.4美元左右,那差不多就是9.5块人民币。耗时差不多10分钟。这样一比较起来,感觉除了写代码,日常的一些AI使用和Agent调用完全可以考虑国内模型。
模型耗时与费用对比
信息抓取
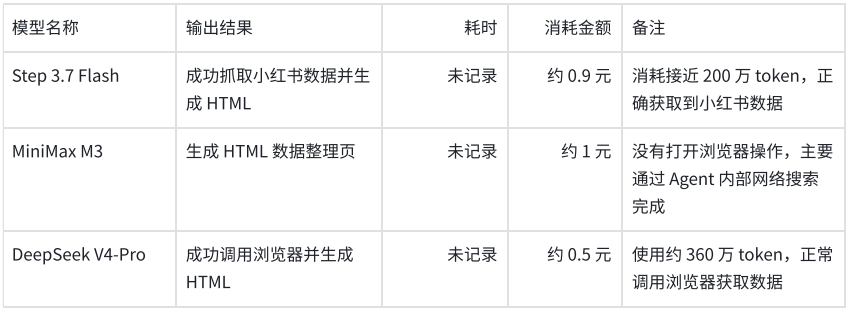
Step-3.7-flash
为什么要测试信息抓取呢?因为这个任务是需要大模型去调用浏览器工具,测试大模型调用单工具,单复杂任务的能力。浏览器信息抓取,需要模型去识别对应的界面标签,比如点赞在什么地方,评论在什么地方,找到对应的标签后,再进行往下面执行。
提示词
到小红书搜索关于即梦的最热门的笔记,选五个整理一下笔记的内容、点赞数和前三条评论整理为一个HTML,放在桌面就行,名字叫“笔记整理”。
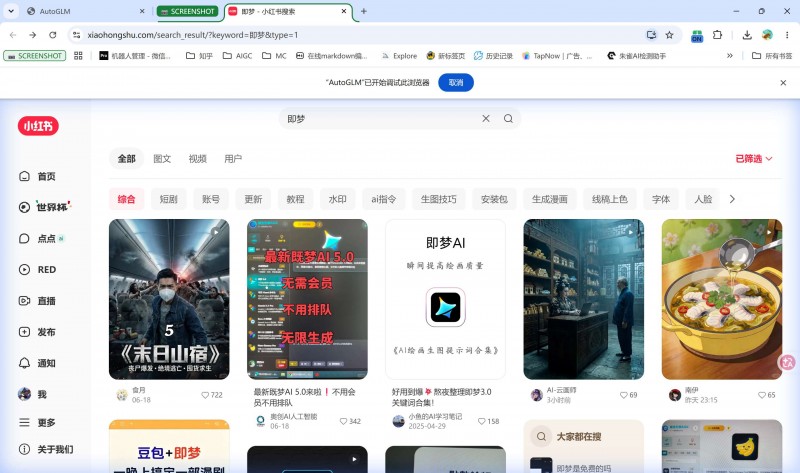
这个浏览器测试任务消耗就比较高了,因为每一步模型都要进行思考下一步应该要干什么,点击什么元素才可以获取到对应的数据。

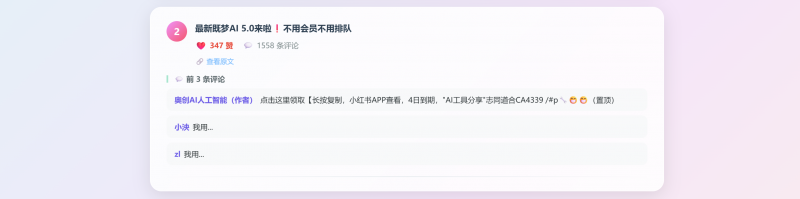
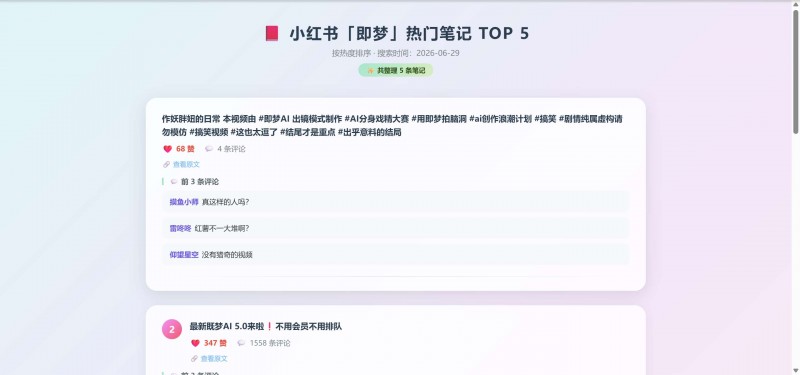
消耗了快200万的token,金额在0.9元左右。 最后制作的效果。
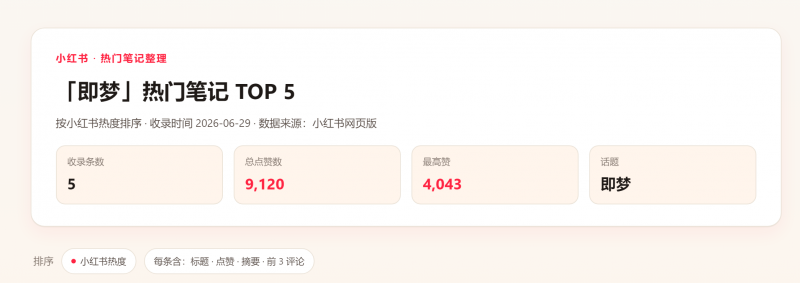
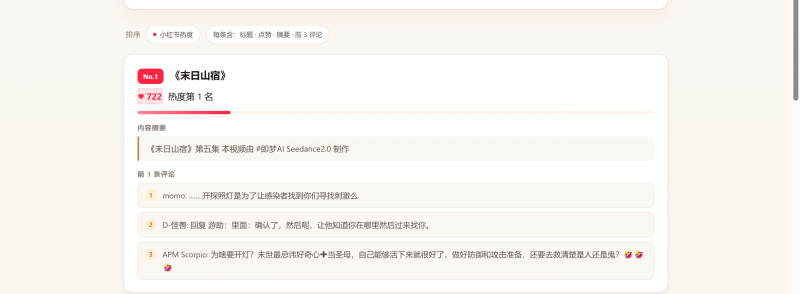
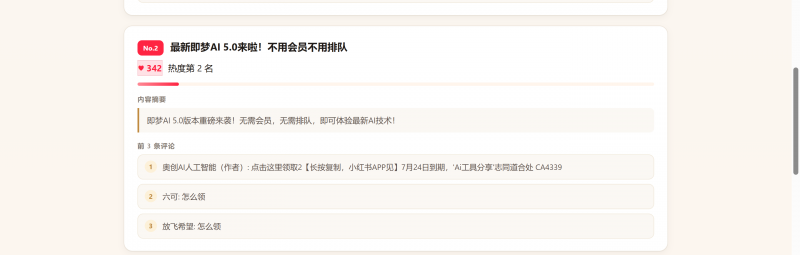
正确获取到了小红书上面的数据。
MiniMax-M3
同样的提示词采用MiniMax-M3进行一次测试。很明显数据和前面的有些不同。不同的原因是因为筛选不一样,MiniMax-M3选用最多点赞进行筛选。Stpe-3.7-flash采用最多评论进行筛选。
消耗金额在一块钱左右。

MiniMax-M3有一个小问题是没有打开浏览器进行操作,在Agent内部使用网络搜索得出的结论。但生成的结果已经可以了。
deepseek-V4-Pro
deepseek-V4-Pro正常调用浏览器去获取数据。
制作的HTML效果。
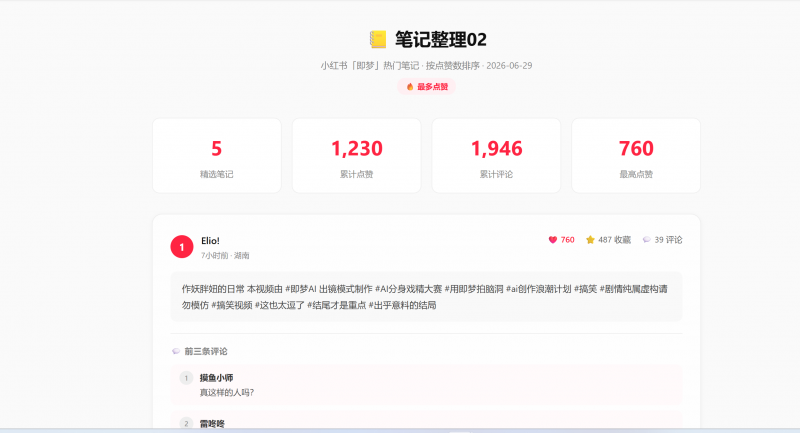
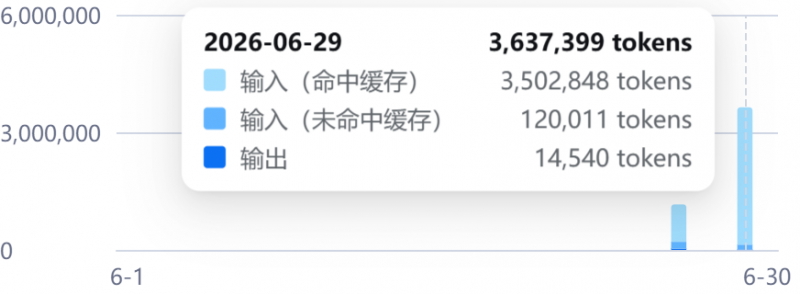
deepseek-V4-Pro使用了360万左右的token,价格在0.5左右。
测试到这里就结束了。
模型耗时与费用对比
最后
前面的测试,主要跑的是一个Agent任务的链路问题——从搜索→阅读→总结→代码生成→再到工具调用,最终输出PPT结果和数据展示。我们重点看的是这套流程是否跑得流畅,以及端到端耗时和单任务成本的高低。
如果只看单次成品,差距可能没那么夸张。但放到生产环境里,差异会被迅速放大。因为Agent任务看的是端到端结果:能不能稳定跑完,跑完要多久,每次调用要多少钱,最后文件能不能直接用。
至少在“高频、明确、可验证”这类Agent任务里,Flash档模型的价值开始凸显。它不追求所有榜单第一,但要在速度、成本和稳定性之间找到一个更实用的平衡点——而这恰恰是生产级场景最在意的三个维度。



